broker servers (each with a unique broker ID) working together to
provide load balancing and fault tolerance. Producers publish messages to topics, each of which is divided into one or
more partitions spread across brokers. Topics with multiple partitions enable horizontal scalability: each partition is
an append-only log, and partitions can be processed in parallel by consumers. Every message within a partition is
assigned a unique, sequential offset that identifies its position. Kafka leverages an efficient TCP-based protocol;
data written by a producer is appended to the end of the log on the leader broker for that partition and replicated to
follower brokers.
Brokers coordinate via ZooKeeper (legacy) or KRaft (new) for cluster metadata and leader election. In older releases,
ZooKeeper maintains the cluster state and elects one broker as the controller and one broker per partition as leader, with
the others as followers. (In KRaft mode, Kafka brokers run an internal consensus using the Raft protocol to manage metadata,
removing the ZooKeeper dependency.) The leader broker of a partition handles all produce/fetch requests; followers replicate
the leader’s log. When brokers join or fail, ZooKeeper (or the KRaft controller quorum) triggers leader elections to assign
a new partition leader. A partition’s replication factor (configured per topic) determines how many copies exist;
for example, RF=3 means one leader and two followers. Any replica that is fully caught up to the leader is called an
In-Sync Replica (ISR). The leader will only consider a write successful when it is persisted to all in-sync replicas
(for acks=all), ensuring durability.
Kafka supports flexible delivery semantics. Producers can set acks=0/1/all to balance latency vs durability; acks=all
(or -1) ensures the leader waits for all ISR acknowledgments. Enabling idempotence on the producer assigns sequence
numbers to records so retries do not produce duplicates, enabling exactly-once delivery to a partition even if retries
occur. Kafka’s core guarantee is that message order is preserved per partition: records within a single partition are
strictly ordered and consumed in order. However, Kafka does not guarantee ordering across different partitions of
the same topic.
Consumers read records from topics by polling brokers. Consumers join a consumer group (identified by a group ID) and
are automatically assigned partition ownership such that each partition is read by only one consumer in the group. The
group coordinator broker manages membership and triggers rebalances whenever consumers join or leave, reassigning
partitions accordingly. Each consumer tracks offsets (positions) of its partitions. Offsets are stored in a special
internal topic (__consumer_offsets), allowing consumers to resume after restarts or failures. Offsets may be committed
automatically or manually; committing offsets only after processing enables at-least-once processing, while transactional
APIs enable exactly-once processing end-to-end.
Communication Model
Kafka follows a publish-subscribe model: producers send messages to topics, and consumers subscribe to those topics to fetch messages. The diagram above illustrates a simple producer-topic-consumer workflow. Topics can have many partitions and multiple producers/consumers simultaneously. Each broker hosts some topic partitions (one leader replica and zero or more follower replicas per partition). When a broker fails, a follower from the ISR takes over as leader, ensuring continued availability and durability. Together, these mechanisms (partitioning, replication, and leader election) give Kafka its high throughput and resilience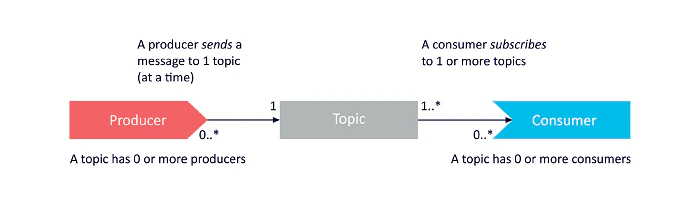
Core Components and Relationships
Topics and Partitions
A topic is a logical category or stream of records. Each topic is divided into ordered partitions. A partition is the unit of parallelism and ordering: producers write and consumers read from a specific partition. Kafka scales by adding partitions and brokers. A topic’s replication factor (≤number of brokers) controls how many copies of each partition exist.Brokers
Each Kafka broker is a server that stores zero or more partitions. Brokers coordinate via ZooKeeper/KRaft for cluster membership and manage reads/writes. When a broker becomes leader for a partition, it handles all client reads/writes for that partition; followers replicate data from the leader. A minimum of three brokers is recommended for reliability.Producers
Producers are client applications that write (publish) records to Kafka topics. They typically batch records in memory (buffered) before sending. Producers choose a partition (often via a key-hash or round-robin) and send asynchronously to the partition’s leader. Producers can compress data (e.g., gzip, snappy, lz4, zstd) to increase throughput. They also manage retries and can use idempotence to avoid duplicate messages on retry.Consumers & Consumer Groups
Consumers read records from Kafka topics. Consumers with the same group.id form a consumer group. Each consumer instance in a group is assigned exclusive ownership of some partitions of the subscribed topics. Within a group, Kafka delivers each partition’s messages to exactly one consumer, enabling parallel processing and scaling reads across instances. Consumers poll brokers for data; Kafka’s pull-based model allows the consumer to control the rate of consumption.Replication and ISR
For each partition, one broker is the leader and zero or more brokers hold follower replicas. Followers asynchronously fetch data from the leader. A follower is in-sync (in the ISR) if it has fully caught up to the leader’s log. The min.insync.replicas setting can require at least k replicas (including leader) to acknowledge writes; if fewer than k replicas are in the ISR, the leader will reject writes when acks=all. This ensures data is durable even if some brokers fail. If a leader fails, one of its followers in the ISR is automatically elected the new leader.ZooKeeper / KRaft
Traditionally, Kafka uses a ZooKeeper ensemble to track brokers, topics, partitions, and ISR membership. ZooKeeper handles controller elections, broker membership (via ephemeral znodes), and stores topic configurations and ACLs. Starting in Kafka 4.x, Kafka can run in KRaft mode, where a quorum of controller nodes uses the built-in Raft protocol to manage metadata, simplifying the architecture by eliminating ZooKeeper.Delivery Semantics, Ordering, and Guarantees
Kafka supports different delivery semantics
- At-Most-Once: Producer does not retry or commit offsets before processing; messages may be lost but never duplicated.
- At-Least-Once: Default mode with retries; ensures no data loss, but may duplicate messages on consumer failure/retry.
- Exactly-Once: Achieved via the idempotent producer and transactional API. An idempotent producer tags each message with a unique sequence number (per producer-partition) so that even if it retries, the broker will de-duplicate duplicates. Using transactions, a producer can send a batch of writes and the consumer’s offset commit to an output topic in one atomic operation, achieving exactly-once processing end-to-end.
Kafka guarantees order within a partition
Producers append records in sequence, and a single consumer reads them in the same order. There is no ordering guarantee across partitions – if the key space is spread across partitions, records with different keys may be consumed out of global order. Therefore, if strict global ordering is required, data should be sent to a single-partition topic or handled at the application layer. Producer acks settings directly affect durability and latency. For higher throughput, one might use acks=1 (leader only) at the cost of potential data loss if the leader fails before replicating. For maximum durability, use acks=all (leader waits for all ISR), which ensures that once acknowledged, even if the leader crashes immediately, another replica has the data. Consumers control their own offset commits; committing after processing ensures at-least-once delivery.Performance & Tuning Strategies
Achieving high performance with Kafka involves tuning producer, broker, and consumer configurations, as well as underlying system resources:- Producer Tuning: Key settings include batch.size, linger.ms, and compression.type. Increasing batch.size (e.g. to 100k–200k bytes) allows larger request batches, improving throughput. Setting linger.ms to a non-zero value (e.g. 5–100 ms) makes the producer wait a short time for more records to batch together, which also boosts throughput. Using compression (such as lz4 or snappy) reduces network and disk IO per message. The tradeoff is slightly higher CPU usage and potential latency. Producers should also manage retries and buffer memory (buffer.memory) appropriately. Using asynchronous send and tuning the number of max.in.flight.requests.per.connection can also increase throughput but must be balanced against potential out-of-order delivery if idempotence is off.
- Consumer Tuning: Consumers should tune fetch and polling parameters. Increasing fetch.min.bytes and fetch.max.bytes allows the broker to return larger batches of data per request. For example, setting fetch.min.bytes=1048576 (1MB) and fetch.max.bytes=100MB can improve throughput by reducing round-trips. Adjust max.partition.fetch.bytes (the max per partition) similarly. Setting max.poll.records higher (e.g. 1000+) lets the consumer process more records per poll, increasing throughput at the cost of higher memory usage. The TCP buffer sizes (receive.buffer.bytes and send.buffer.bytes) can be raised (e.g. 1MB) to improve throughput on high-latency networks. Consumers should also tune enable.auto.commit and the commit interval to balance between throughput and failure recovery.
- Broker / Cluster Tuning:
- Threads: Configure the broker’s num.network.threads (handles socket I/O) and num.io.threads (processes I/O from the socket queue) to match hardware and workload. As a rule of thumb, start num.io.threads at about 8× the number of disks. Monitor broker metrics (e.g. NetworkProcessorAvgIdlePercent) to see if threads are a bottleneck. Adjust queued.max.requests to limit request queue length if needed.
- Memory: Kafka relies heavily on the OS page cache. All writes go to the page cache first (without immediate fsync). Ensure the machine has plenty of RAM (e.g. 64GB) so the OS can cache data. Kafka brokers typically need only moderate JVM heap (6–8GB), leaving most RAM for caching.
- Disks: Use multiple dedicated drives (SSD or fast HDD) for log directories. Separate Kafka data files from OS/filesystem logs to avoid contention. You can use JBOD or RAID10; RAID10 is recommended for both performance and fault tolerance. XFS or EXT4 are the preferred filesystems. Avoid network file systems (NAS) due to higher latency and single points of failure. For high throughput, consider disabling fsync (Kafka flushes according to flush.messages/flush.ms) and tuning OS settings (e.g. fs.file-max, ulimit -n, vm.swappiness=1).
- Network: Ensure a low-latency, high-bandwidth network (10GbE or better) between brokers and clients. Increasing the broker’s socket buffers (socket.send.buffer.bytes and socket.receive.buffer.bytes, e.g. to 1MB) can improve throughput on high-latency links. Use a reliable network fabric to minimize packet loss.
- Kafka Config: Tune broker configs like log.segment.bytes and log.retention.* to control segment size and deletion. Set default.replication.factor=3 and min.insync.replicas=2 for production topics to ensure data durability. Disable automatic topic creation in production (auto.create.topics.enable=false) to enforce proper partitioning/replication. For internal topics (__consumer_offsets, __transaction_state), ensure enough partitions and replicas (e.g. offsets topic often has 50+ partitions and RF=3) to handle group coordination.
- ZooKeeper/KRaft: In older setups, tune the ZooKeeper ensemble (e.g. 3 nodes, tuned JVM/Garbage Collection, and network). For new deployments, use KRaft mode and run multiple controller nodes (e.g. 3) to avoid external dependencies. Ensure the controller quorum has enough capacity to handle metadata operations.
Fault Tolerance and Reliability
Kafka is designed for high availability. Key strategies include:- Replication: As noted, partitions are replicated to multiple brokers. A replication factor of ≥3 is common. Replicas on different racks/data centers increase resilience to failures.
- Controller & Leader Election: One broker (the controller) manages partition leadership. If any broker fails, ZooKeeper/KRaft automatically triggers a new leader election so another replica takes over, minimizing downtime.
- In-Sync Replicas: By configuring min.insync.replicas, producers can require a write to be acknowledged by multiple nodes, guarding against loss when a leader crashes. If the ISR falls below this threshold, the leader will refuse writes (for acks=all) to avoid data risk.
- Data Integrity: With idempotent producers and transactions, Kafka provides end-to-end exactly-once guarantees, crucial for critical pipelines. Internally, Kafka uses checksums to detect data corruption.
- Recovery: Upon restart, Kafka fast-forwards a recovering broker’s logs from its local data (or syncs missing parts from leaders) so it rejoins the ISR. The unclean.leader.election.enable setting (usually false) prevents choosing an out-of-sync replica as leader.
- Multi-DataCenter Replication: Tools like MirrorMaker or Confluent Replicator can replicate topics across clusters (active-active or active-passive) for disaster recovery. Geo-replication strategies ensure low-latency reads in each region and continued availability if one site fails.
Common Kafka Interview Topics and Questions
System-Design Scenarios
- Design a high-throughput log ingestion pipeline: How to set up Kafka to collect logs (e.g. web/app logs) at scale. Key points: producers on each service/server with batching, use of appropriate partition counts to parallelize, replication factor (≥3) for durability, durable brokers on fast disks, and a scaled-out consumer layer (perhaps using Kafka Streams or Spark) to process logs downstream. Consider partitioning scheme (e.g. by source or time) and how to handle late or out-of-order data.
- Scaling a Kafka cluster: Describe adding brokers and rebalancing partitions. How to increase partitions for a topic to parallelize consumers, how to redistribute existing partitions evenly across brokers (using kafka-reassign-partitions.sh). Emphasize zero-downtime scaling: producers/consumers use a bootstrap server list and will discover new brokers automatically.
- Exactly-Once Delivery: Explain Kafka’s idempotent producer and transactional features. Discuss setting enable.idempotence=true, how Kafka assigns producer IDs and sequence numbers to prevent duplication geeksforgeeks.org . For processing pipelines, describe using the Streams API or Kafka transactions to write data and commit offsets atomically.
- Fault Tolerance: How Kafka handles broker failures (ISR, leader election). Ensuring data durability with replication. Discuss controller failover, avoiding data loss with acks=all and sufficient ISRs. Multi-rack deployments and rack-aware partition placement for AZ redundancy.
- Use Cases: Kafka as a commit log (e.g. for event sourcing), log aggregation (replacing syslog/Flume), metric ingestion, real-time stream processing.
- Kafka vs Traditional Messaging: Contrast Kafka with JMS brokers or RabbitMQ: Kafka is durable log-based and pull-based, whereas many MQs are broker queues with acknowledgments. Kafka offers higher throughput and built-in partitioning/replication kafka.apache.org . There are no per-message ACKs from the broker to confirm consumption; instead consumers track offsets. Kafka decouples storage from consumption, allowing multiple consumers to independently replay data. (Kafka is often described as a distributed commit log rather than a simple queue.)
Theoretical Kafka Questions
- Log Compaction vs Retention: Explain that normal retention deletes old messages by time or size regardless of content. By contrast, log compaction (cleanup.policy=compact) retains only the latest value for each key, removing older duplicates. This provides a per-key “latest state” log, useful for changelogs or snapshots.
- Data Ordering: Kafka guarantees order only within a partition, not across partitions. If global ordering is needed, data must be keyed or sent to the same partition.
- Message Delivery Semantics: Kafka can provide at-least-once delivery by default; exactly-once via idempotent producer and transactions; at-most-once if consumers skip offset commit. Explain how producer acks and retries, plus consumer commit modes, affect semantics.
- Idempotence and Transactions: What is an idempotent producer and how does it avoid duplicates? How do transactions work (the transactional.id setting, internal transaction log topic)?
- Consumer Offset Management: How offsets are stored and committed (automatically or manually), and how Kafka uses the __consumer_offsets topic. The role of the group coordinator and the rebalance protocol on consumer failure.
- Partitioners: Round-robin vs key-based partitioning: Key-based ensures same key goes to same partition (so ordering per key), while round-robin balances load.
- Kafka Streams vs Other Processing: (Less central here, but possible.) Kafka Streams for stateful processing (with exactly-once) vs. external systems like Spark/Flink.
- ZooKeeper/KRaft: The role of ZooKeeper (controller election, cluster metadata) vs. the new KRaft-based controller. How many ZooKeeper or controller nodes are needed for resilience.
- Monitoring and Metrics: Common metrics (lag, ISR count, active controller, under-replicated partitions) – though this is more operational than interview theoretical.