Replication means keeping a copy of the same data on multiple machines that are connected via a network.
- To keep data geographically close to your users (and thus reduce latency)
- To allow the system to continue working even if some of its parts have failed (and thus increase availability)
- To scale out the number of machines that can serve read queries (and thus increase read throughput)
Leader-Based Replication
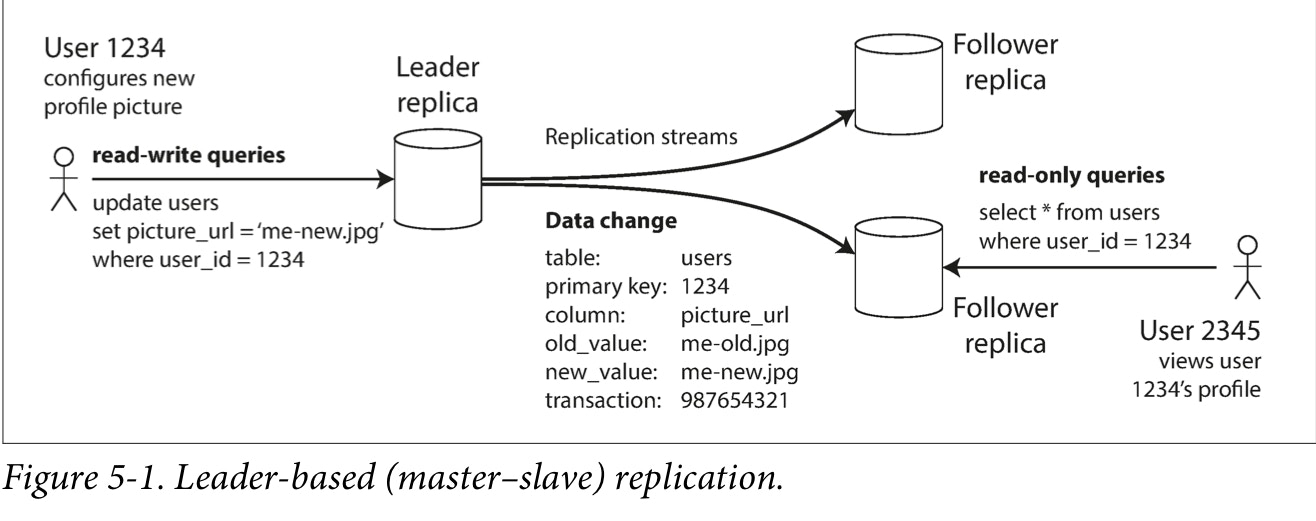
Master-slave replication
The master serves reads and writes, replicating writes to one or more slaves, which serve only reads. Slaves can also replicate to additional slaves in a tree-like fashion. If the master goes offline, the system can continue to operate in read-only mode until a slave is promoted to a master or a new master is provisioned.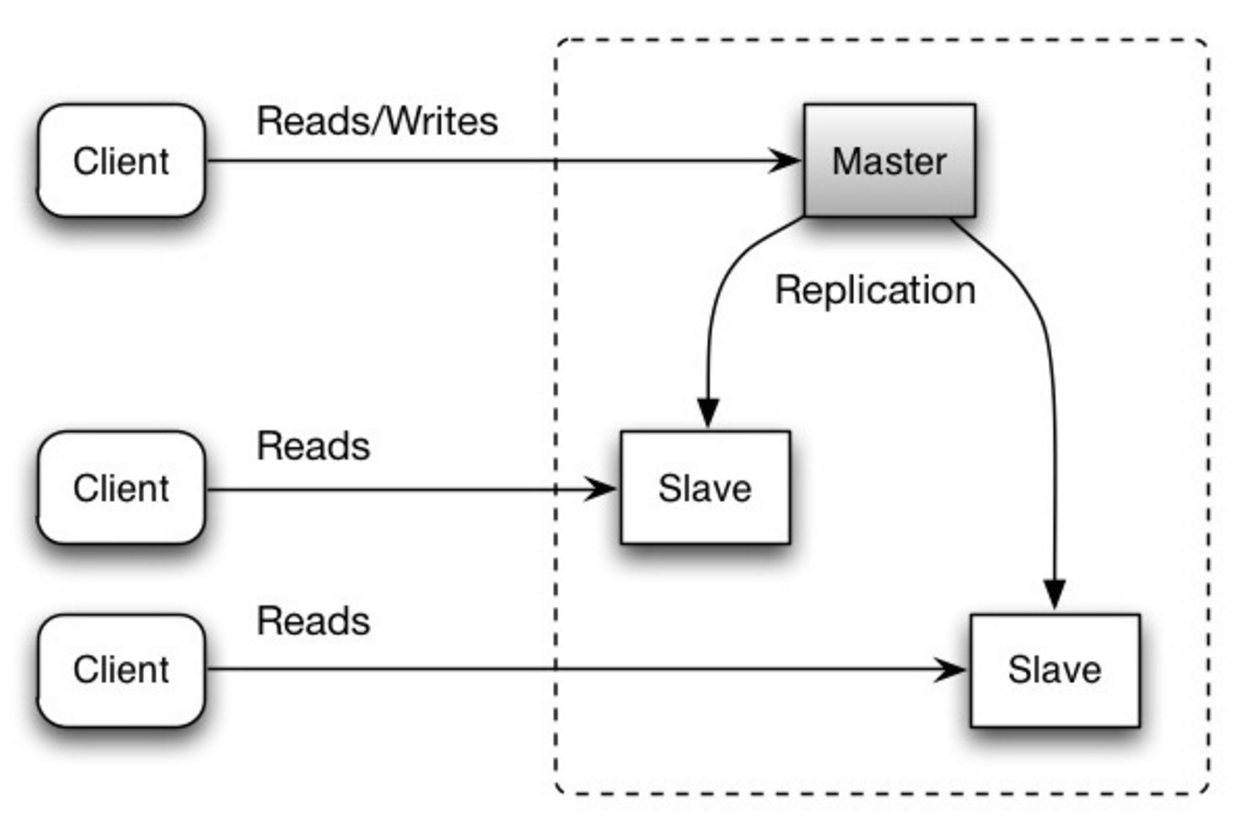
Synchronous vs Asynchronous Replication
Often, leader-based replication is configured to be completely asynchronous
Setting up New Followers
Handling Node Outage
Follower failure: Catch-up recovery
Master failure: Failover
Replication Lag and Eventual Consistency
Read-After-Write Consistency
Cross-Device Read-After-Write Consistency
Monotonic Reads
An anomaly that can occur when reading from asynchronous followers is that it’s possible for a user to see things moving backward in time. This can happen if a user makes several reads from different replicas. For example, Figure 5-4 shows user 2345 making the same query twice, first to a follower with little lag, then to a follower with greater lag. (This scenario is quite likely if the user refreshes a web page, and each request is routed to a random server.) The first query returns a comment that was recently added by user 1234, but the second query doesn’t return anything because the lagging follower has not yet picked up that write.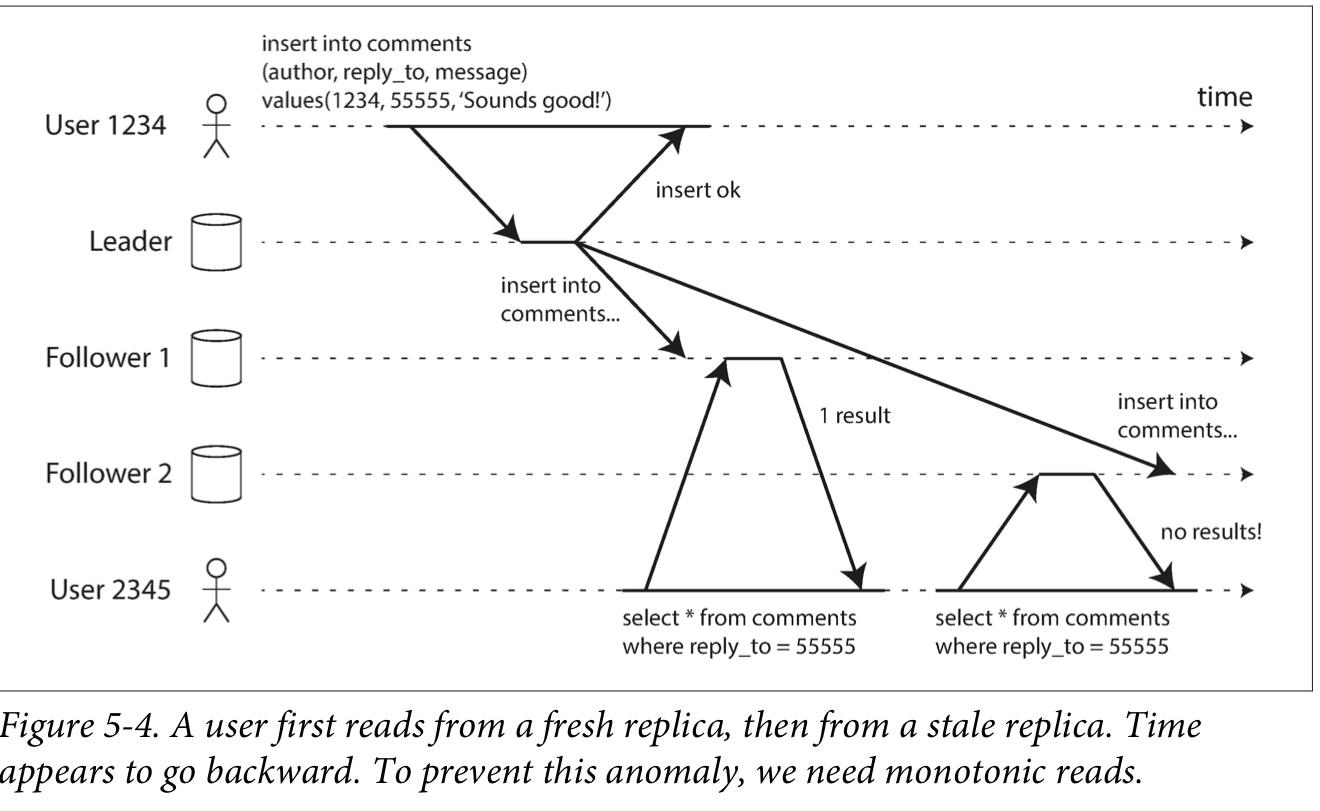
Consistent Prefix Reads
Master-Master replication
Both masters serve reads and writes and coordinate with each other on writes. If either master goes down, the system can continue to operate with both reads and writes.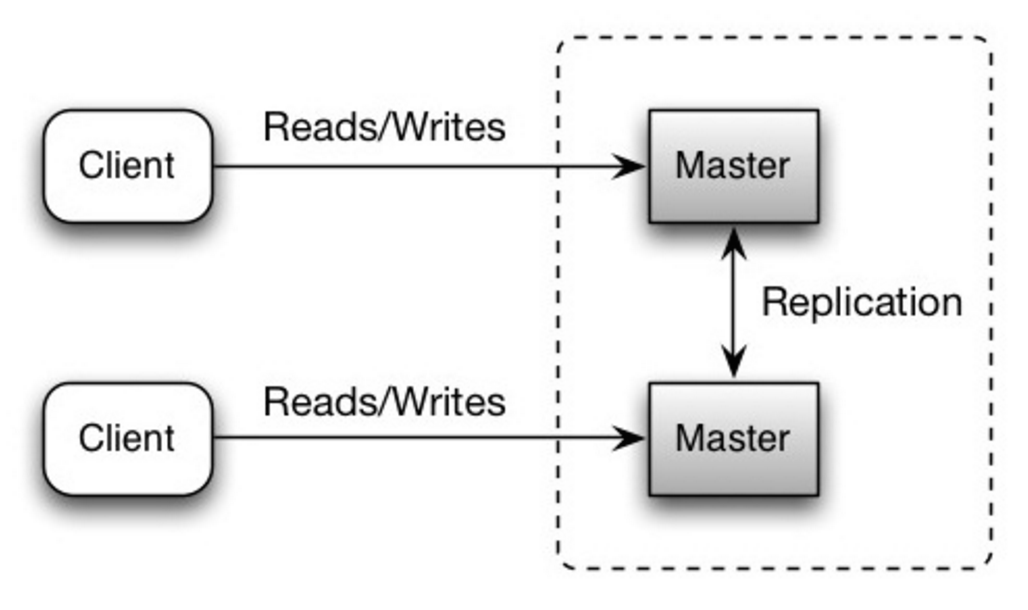
It rarely makes sense to use a multi-leader setup within a single datacenter, because
the benefits rarely outweigh the added complexity. However, there are some situa‐
tions in which this configuration is reasonable.
Use Cases of Multi-Leader Replication
- Multi-Datacenter operation
- Clients with offline opertions
- Collaborative editing
Handling Write Conflicts
The biggest problem with multi-leader replication is that write conflicts can occur, which means that conflict resolution is required.Conflict Detection (Synchronous vs Asynchronous)
Conflict Avoidance
Topologies
A replication topology describes the communication paths along which writes are propagated from one node to another. If you have two leaders, like in Figure 5-7, there is only one plausible topology: leader 1 must send all of its writes to leader 2, and vice versa. With more than two leaders, various different topologies are possible.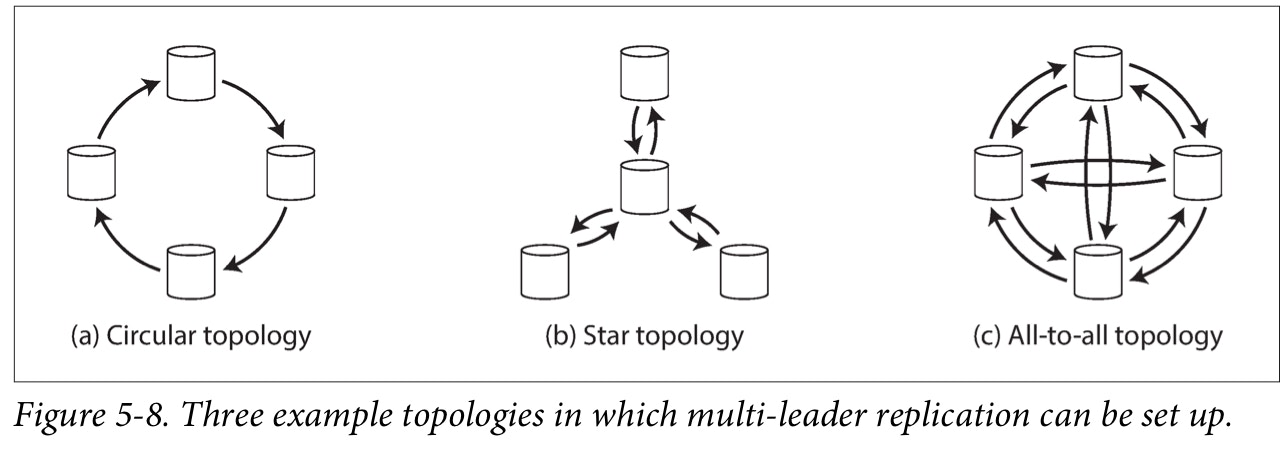
- You’ll need a load balancer or you’ll need to make changes to your application logic to determine where to write.
- Most master-master systems are either loosely consistent (violating ACID) or have increased write latency due to synchronization.
- Conflict resolution comes more into play as more write nodes are added and as latency increases.
Leaderless Replication
The replication approaches we have discussed so far in this chapter—single-leader and multi-leader replication—are based on the idea that a client sends a write request to one node (the leader), and the database system takes care of copying that write to the other replicas. A leader determines the order in which writes should be processed, and followers apply the leader’s writes in the same order. Some data storage systems take a different approach, abandoning the concept of a leader and allowing any replica to directly accept writes from clients. Some of the ear‐ liest replicated data systems were leaderless, but the idea was mostly forgotten during the era of dominance of relational databases. It once again became a fashiona‐ ble architecture for databases afterAmazon used it for its in-house Dynamo system.vi Riak, Cassandra, and
Voldemort are open source datastores with leaderless
replication models inspired by Dynamo, so this kind of database is also known as
Dynamo-style.In some leaderless implementations, the client directly sends its writes to several rep‐ licas, while in others, a coordinator node does this on behalf of the client. However, unlike a leader database, that coordinator does not enforce a particular ordering of writes. As we shall see, this difference in design has profound consequences for the way the database is used.
Writing to a database when a node is down
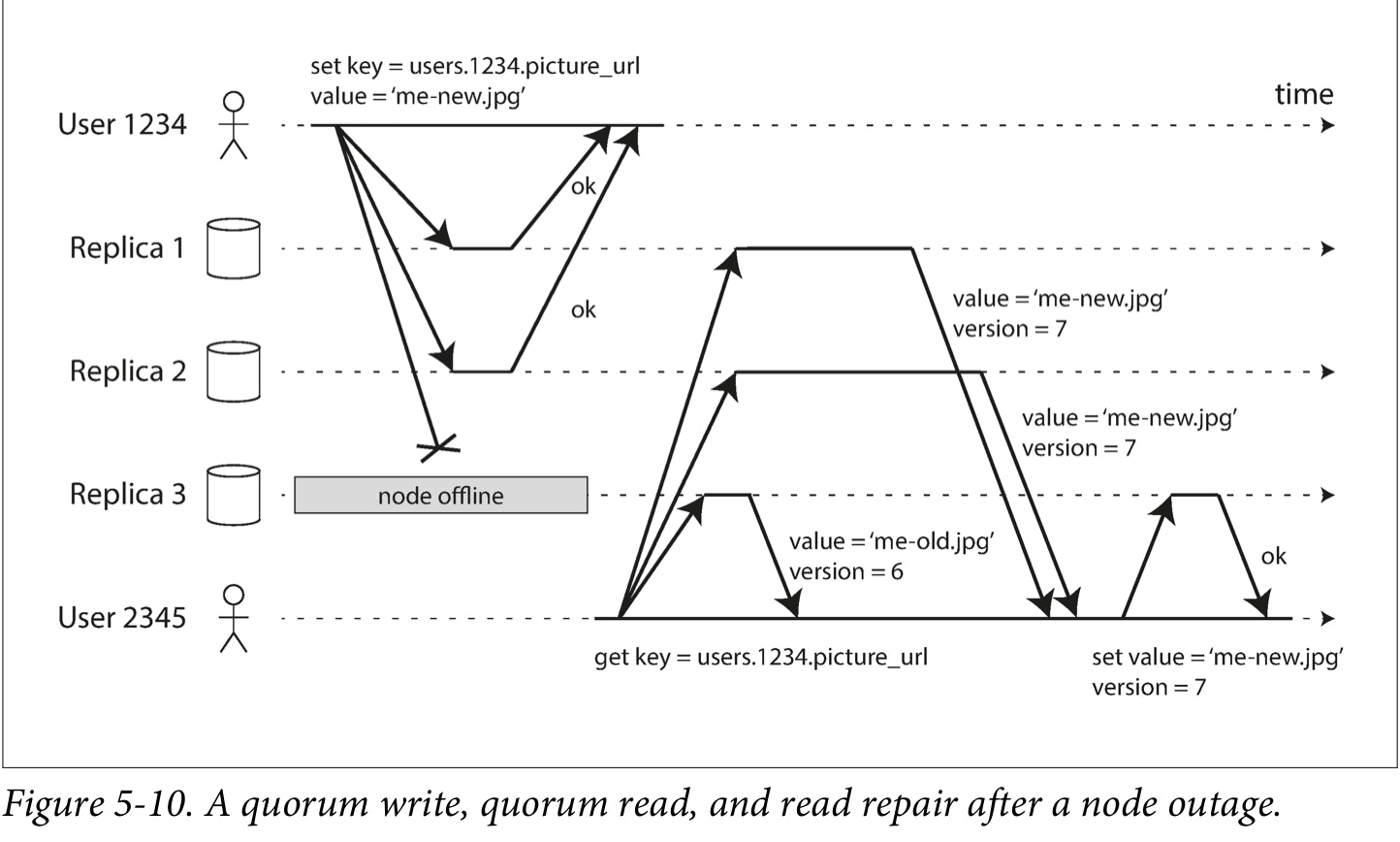
In a leader-based config, if you want ti continue processing writes, you may need to perform a failover.On the other hand, in a leaderless configuration, failover does not exist. Figure 5-10 shows what happens: the client (user 1234) sends the write to all three replicas in par‐ allel, and the two available replicas accept the write but the unavailable replica misses it. Let’s say that it’s sufficient for two out of three replicas to acknowledge the write: after user 1234 has received two ok responses, we consider the write to be successful. The client simply ignores the fact that one of the replicas missed the write.
Read repairs and anti-antropy
- Read repair
- Anti-antropy
Quorums for reading and writing
Limitations of Quorum Consistency
Detecting Concurrent writes
Disadvantage(s): replication- There is a potential for loss of data if the master fails before any newly written data can be replicated to other nodes.
- Writes are replayed to the read replicas. If there are a lot of writes, the read replicas can get bogged down with replaying writes and can’t do as many reads.
- The more read slaves, the more you have to replicate, which leads to greater replication lag.
- On some systems, writing to the master can spawn multiple threads to write in parallel, whereas read replicas only support writing sequentially with a single thread.
- Replication adds more hardware and additional complexity.